

Several open source tools allow the extraction of clean text from article HTML. We list the most popular ones below, and run a benchmark to see how they stack up against the Ujeebu API.
Extracting clean article text from blogs and news sites (a.k.a. boilerplate removal) comes in handy for a variety of applications such as offline reading, article narration and generating article previews. It is also often a prerequisite for further content processing such as sentiment analysis, content summarization, text classification and other tasks that fall under the natural language processing (NLP) umbrella.
Why is boilerplate removal a difficult problem?
The main difficulty in extracting clean text from html lies in determining which blocks of text contribute to the article; different articles use different mark-up, and the text can be located anywhere in the DOM tree. It is also not uncommon for the parts of the DOM that contain the meat of the article to not be contiguous, and include loads of boilerplate (ads, forms, related article snippets...). Some publications also use JavaScript to generate the article content to ward off web scrapers, or simply as a coding preference.
Articles contain other important info like author and publication date, which are also not straightforward to extract. Take the example of dates. Though you can achieve rather decent date extraction with regular expressions, you might need to identify the actual publication date vs. some other date mentioned in the article. Furthermore, one would need to run tens of regular expressions per supported language, and in doing so dramatically affect performance.
So how do you extract text and other data from a web page?
Two sets of techniques are commonly used: statistical and Machine Learning based. Most statistical methods work by computing heuristics like link density, the frequency of certain characters, distance from the title, etc..., then combining them to form a probability score that represents the likelihood that an html block contains the main article text. A good explanation of these techniques can be found here. Machine learning techniques on the other hand rely on training mathematical models on a large set of documents that are represented by their key features and feeding them into a ML model.
Both techniques have their merits, with the statistical/heuristics method being the less computationally intensive of the two, on top of providing acceptable results in most cases. ML based techniques on the other hand tend to work better in complex cases and perform well on outliers, however as with any Machine Learning based algorithms, the quality of the training data is key. The two techniques are also sometimes used in tandem for better accuracy.
In some cases, extractors can fail due to a never-seen-before html structure, or simply bad mark-up. In such cases, it's customary to use per-domain rules that rely on CSS and/or DOM selectors. This is obviously a site dependent technique, and cannot be standardized by any means, but might help if we're scraping a small set of known publications, and provided regular checks are performed to make sure their html structure didn't change.
The Open source offering
Readability
Readability is one of the oldest and probably the most used algorithms for text extraction, though it has considerably changed since it was first released. It also has several adaptations in different languages.
Mercury
Mercury is written in JavaScript and is based on Readability. It is also known for using custom site rules.
BoilerPipe
BoilerPipe is Java based, uses a heuristics based algorithm just like readability and can be demo'ed here.
DragNet
DragNet uses a combination of heuristics and a Machine Learning Model. It comes pre-trained out of the box but can also be trained on a custom data set.
NewsPaper
NewsPaper is written in Python and is based on a package called Goose, which is also another decent extractor written in Scala. NewsPaper offers the advantage of extracting other data pieces like main keywords and article summary.
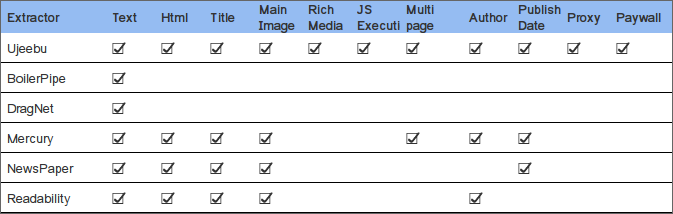
Ujeebu vs. Open Source
Ujeebu uses heuristics much like the other packages, from which it draws heavily, but resorts to a model to determine which heuristics to use. It also uses a model to determine if JavaScript is needed. This is paramount since JavaScript execution can dramatically slow down the extraction process, so it's important to know if it's needed or not upfront. Ujeebu supports extraction on multi-page articles, can identify rich media on demand and has built-in proxy and IP rotation.
In what follows, we compare the capabilities of Ujeebu with those of open source tools.
Performance
We ran Ujeebu and the aforementioned open source packages against a list of 338 URLs, then compared their output against the manually extracted version of those articles. Our sample represents 9 of the most languages on the Web. Namely, English, Spanish, Chinese, Russian, German, French, Portuguese, Arabic and Italian.
On the open source front, Readability stands out on top. We used the default version of DragNet, so the results were not the greatest, but pretty sure we could have had (much) better results had we trained it on our own multilingual model. Mercury on the other hand performed pretty well on western languages, but didn't do as well on Arabic, Russian and Chinese.
Ujeebu scores better across the board and on all languages, slightly outperforming Readability on text and html extraction, but besting all extractors on the rest of data with a large margin.
The extraction scores (out of 100) are based on computing text similarity between each extractor's output and the manual data set:
| Extractor | Text | Title | Author | Publication Date |
|---|---|---|---|---|
| Ujeebu | 95.21 | 91.4 | 61.52 | 48.63 |
| Boilerpipe | 88.92 | - | - | - |
| DragNet | 75.95 | - | - | - |
| Mercury | 62.76 | 60.92 | 12.5 | 25.65 |
| NewsPaper | 90.07 | 92.5 | - | 26.76 |
| Readability | 94.85 | 87.84 | 32.64 | - |
Conclusion
While the current open source offering exhibits decent performance for text extraction, Ujeebu extracts more info from articles, and incorporates several capabilities from the get go which would require substantial effort to get right if done in-house (pagination, rich media, rendering js heavy pages, using a proxy, etc...).
Don't take our word for it though, feel free to experiment with our test set here, try Ujeebu for yourself on our demo page, or get your own trial key and get started by using one of our several examples in the language of your choice.
