

Introduction
Curious about how to scrape data from Google's Search Engine Results Pages (SERPs)? In this comprehensive guide, you'll discover how Google SERPs are structured, the essential tools for automated scraping, like Playwright for JavaScript rendering, and how to parse dynamic content. We'll walk through a real-world code example, highlight the common pitfalls of extracting data from Google's HTML, and share best practices for ethical, responsible data collection. By the end, you'll have a solid foundation for building or refining your own Google SERP scraper, along with an understanding of the relevant challenges and considerations for staying compliant.
Understanding the Structure of Google SERPs
Google SERPs are complex, dynamically generated pages comprising various elements. Understanding these components is crucial for effective scraping:
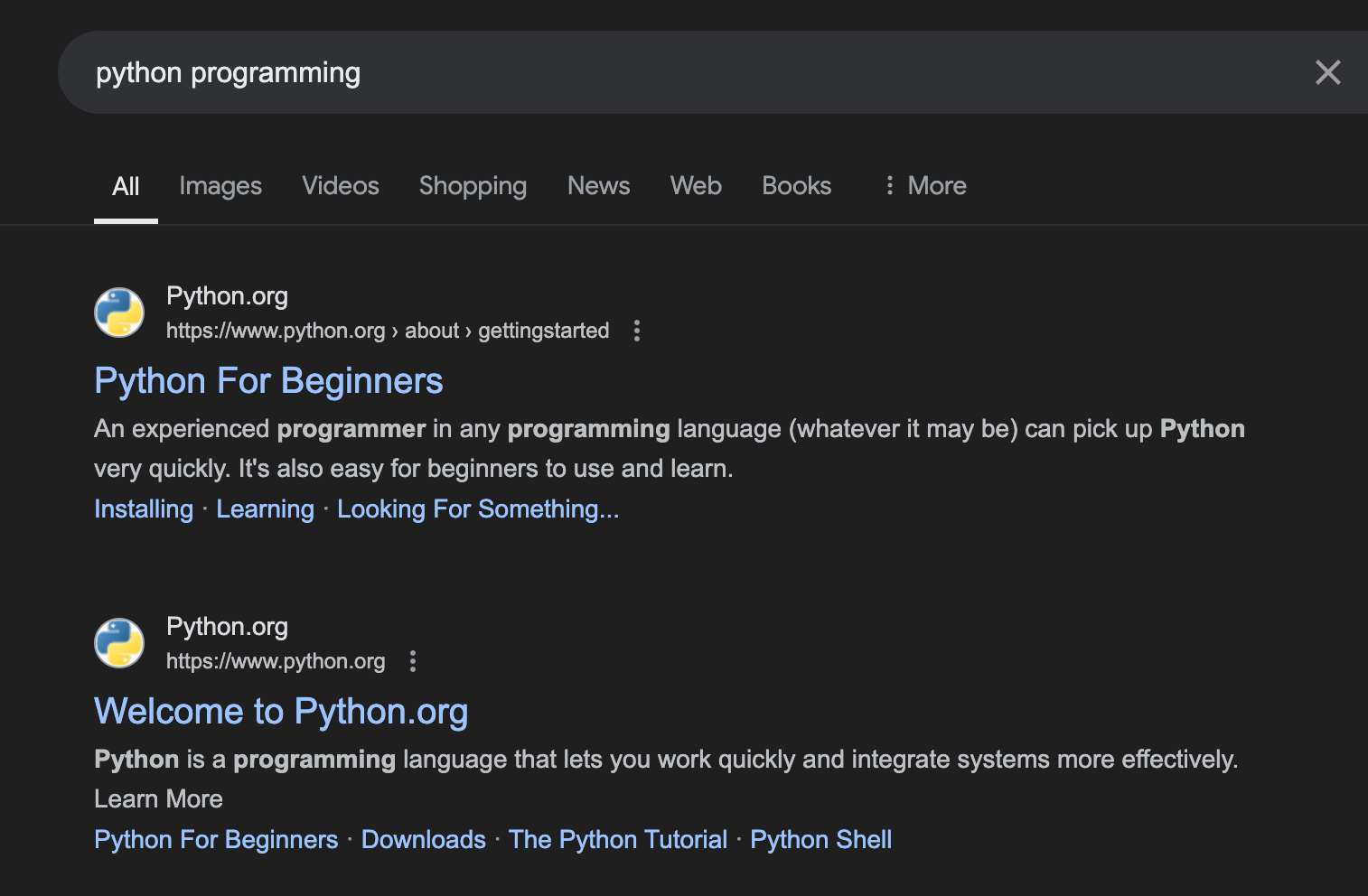
- Organic Search Results:
- Structure: Title, URL, and snippet
- Data points: Title text, URL, snippet text, position in SERP
2. Featured Snippets:
- Types: Paragraph, list, table, or video
- Data points: Content, source URL, position
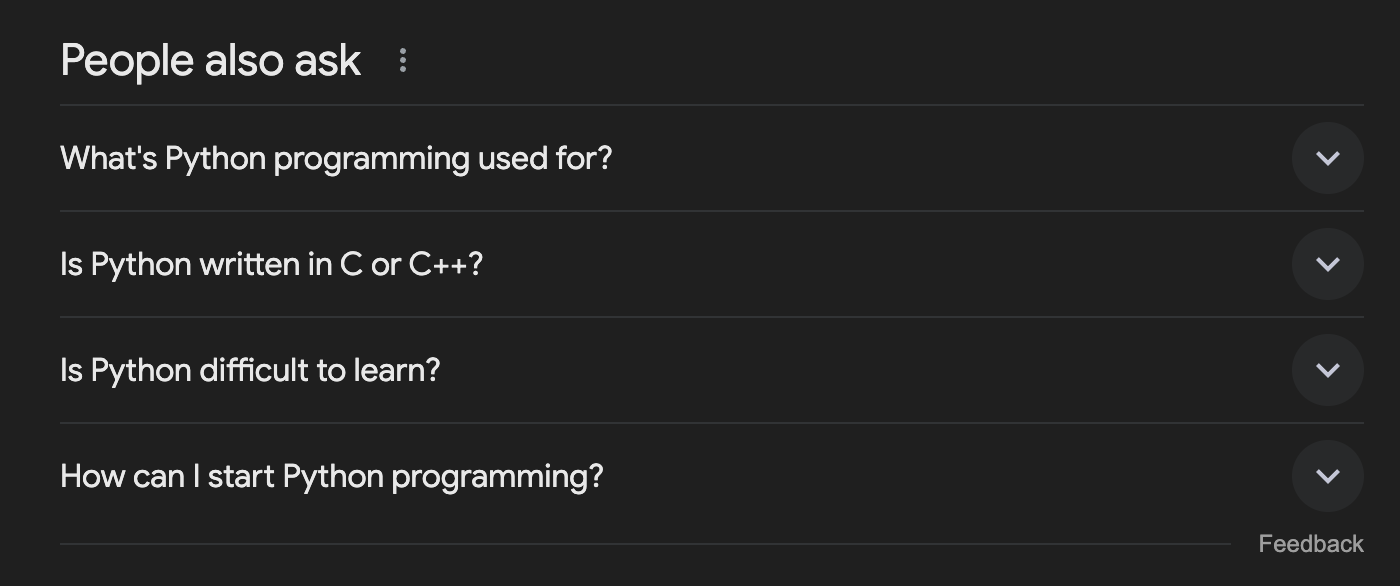
3. People Also Ask (PAA) Boxes:
- Structure: Expandable questions with answers
- Data points: Question text, answer text, source URL
4. Local Pack Results:
- Structure: Map view with local business listings
- Data points: Business names, addresses, phone numbers, ratings
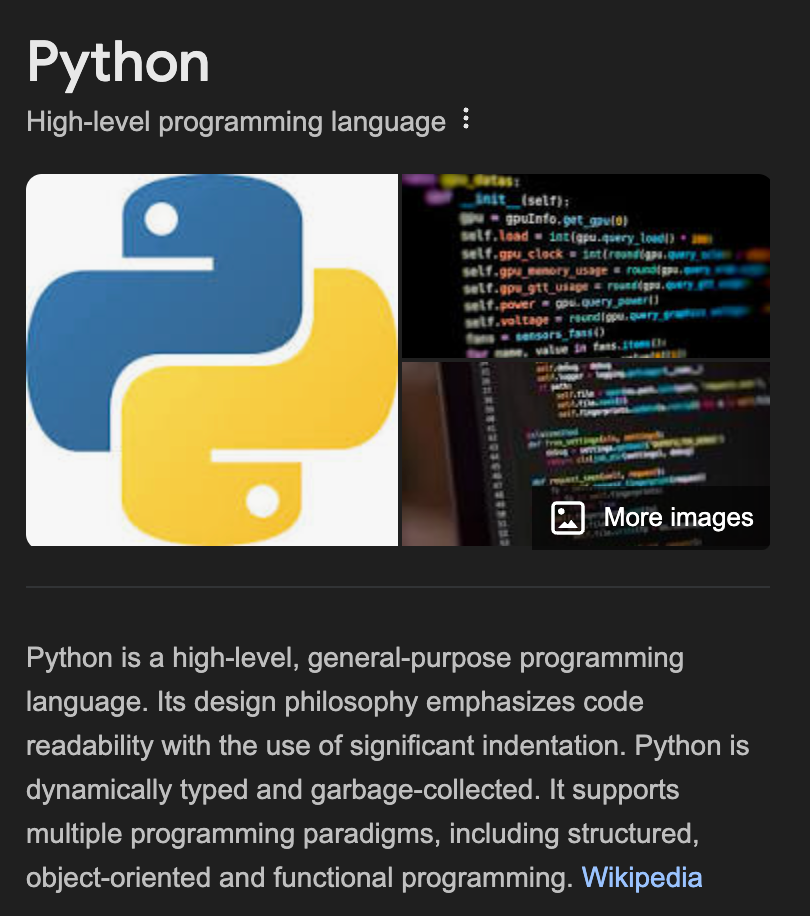
5. Image and Video Results:
- Presentation: Grid layout or inline with organic results
- Data points: Image/video URLs, alt text, source website
6. Related Searches:
- Location: Usually at the bottom of the SERP
- Data points: Related search query texts
7. Advertisements:
- Locations: Top, bottom, or inline with organic results
- Data points: Ad text, display URL, destination URL, ad extensions
Which data of Google SERP can be scraped?
Before diving into the scraping process, it's essential to understand what data you can extract from Google SERPs. Here's a list of 'scrapeable' elements:
- Organic search results
- Title
- URL
- Description (snippet)
- Position in SERP - Paid search results (ads)
- Ad title
- Ad URL
- Ad description - Featured snippets
- Content
- Source URL - People Also Ask (PAA) boxes
- Questions
- Answers - Knowledge Graph information
- Entity name
- Description
- Related images - Local Pack results
- Business names
- Addresses
- Phone numbers
- Ratings - Image results
- Image URLs
- Alt text
- Source websites - Video results
- Video titles
- Thumbnails
- Source (e.g., YouTube) - News results
- Article titles
- Publication names
- Publication dates - Related searches
How to Scrape Google Search Results?
Here is a step-by-step explainer of the code needed to achieve this. We have chosen to use Python because of the ease of use of its libraries, but you can find equivalent libraries/functionality in virtually any other language.
Step 1: Import the necessary libraries
import asyncio
import random
import time
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
asyncioandrandomfor asynchronous execution and adding small delays.playwright.async_apifor automating a headless browser- The
requestslibrary is used to send HTTP requests to the Google search page. - The
BeautifulSouplibrary is used to parse the HTML content of the page.
Step 2: Define the search query and Google domains to exclude
query = "python programming"
google_domains = (
'https://www.google.',
'https://google.',
'https://webcache.googleusercontent.',
'http://webcache.googleusercontent.',
'https://policies.google.',
'https://support.google.',
'https://maps.google.',
'https://m.youtube.com',
'https://www.youtube.com'
)- The
queryvariable is set to the search query "python programming". - The
google_domainsarray is defined to exclude links that point to Google's own domains. We also excluded YouTube videos to only keep text page links.
Step 3: Launch a headless browser with a realistic user agent
Google search result pages are JavaScript heavy, and the results are rendered dynamically upon page load. We therefore need to use a headless browser to emulate a real browser and execute JavaScript.
browser = await p.chromium.launch(headless=True)
context = await browser.new_context(
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.3"
),
locale="en-US"
)
await context.set_extra_http_headers({
"Accept-Language": "en-US,en;q=0.9"
})
page = await context.new_page()
Step 4: Navigate to Google's search page and wait for full rendering
We build the query URL, then instruct Playwright to wait for network requests to settle (wait_until="networkidle"), followed by a small random delay to appear less bot-like.
url = f"https://www.google.com/search?q={query}"
await page.goto(url, wait_until="networkidle")
# Random delay of 2–5 seconds
await asyncio.sleep(random.uniform(2.0, 5.0))
Step 5: Retrieve the final HTML and parse it with BeautifulSoup
html_content = await page.content()
soup = BeautifulSoup(html_content, 'html.parser')
Step 6: Extract only the relevant links and display them
We look for <a> tags where the hrefstarts with"http" or "https" (i.e., direct external links), and skip any known Google-owned domains and YouTube video results, then print out the remaining links.
a_tags = soup.find_all('a', href=True)
absolute_links = []
for a_tag in a_tags:
href = a_tag['href']
# If it starts with http (i.e., an external link rather than a local or anchor link)
if href.startswith("http"):
if not any(domain in href for domain in google_domains):
absolute_links.append(href)
for link in absolute_links:
print(link)
- The
find_all()method is used to extract all<a>tags with anhrefattribute. - The
href=Trueargument specifies that we only want to extract tags with anhrefattribute. - The extracted tags are stored in the
absolute_linksvariable.
Putting It All Together
The final Code looks like this – Remember that scraping Google may violate Google’s Terms of Service, and you can be blocked or served a CAPTCHA:
import asyncio
import random
import time
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
async def fetch_rendered_html(url: str) -> str:
async with async_playwright() as p:
# Launch headless Chromium
browser = await p.chromium.launch(headless=True)
# Create a browser context with a realistic user agent & locale
context = await browser.new_context(
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.3"
),
locale="en-US",
)
# Set additional headers (Accept-Language, etc.)
await context.set_extra_http_headers({
"Accept-Language": "en-US,en;q=0.9"
})
page = await context.new_page()
# Go to the URL and wait for network activity to settle
await page.goto(url, wait_until="networkidle")
# Small random delay (to appear slightly less "bot-like")
await asyncio.sleep(random.uniform(2.0, 5.0))
# Grab the final rendered HTML
html_content = await page.content()
# Close the browser
await browser.close()
return html_content
async def scrape_google_links(query: str):
# Construct the Google search URL
url = f"https://www.google.com/search?q={query}"
# Fetch the final rendered HTML
html_content = await fetch_rendered_html(url)
# Parse with BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Find all <a> tags with an href
a_tags = soup.find_all('a', href=True)
# Domains to skip (including video search results)
google_domains = (
'https://www.google.',
'https://google.',
'https://webcache.googleusercontent.',
'http://webcache.googleusercontent.',
'https://policies.google.',
'https://support.google.',
'https://maps.google.',
'https://m.youtube.com',
'https://www.youtube.com'
)
absolute_links = []
for a_tag in a_tags:
href = a_tag['href']
# If it starts with http (i.e., an external link rather than a local or anchor link)
if href.startswith("http"):
if not any(domain in href for domain in google_domains):
absolute_links.append(href)
return absolute_links
def main():
query = "python programming"
print(f"Scraping Google search results for: {query}")
# Run the async function once
start = time.time()
links = asyncio.run(scrape_google_links(query))
end = time.time()
print(f"Time taken: {end - start:.2f}s\n")
print("Extracted Links:")
for link in links:
print(link)
if __name__ == "__main__":
main()
The Output:
Scraping Google search results for: python programming
Time taken: 7.72s
Extracted Links:
https://trends.google.com/trends/explore?date=today%205-y&q=python programming
https://www.python.org/about/gettingstarted/
https://www.coursera.org/articles/what-is-python-used-for-a-beginners-guide-to-using-python#:~:text=Python%20is%20commonly%20used%20for,everyday%20tasks%2C%20like%20organizing%20finances.
https://www.datacamp.com/blog/how-to-learn-python-expert-guide#:~:text=While%20Python%20is%20one%20of,you%20can%20dedicate%20to%20learning.
https://www.quora.com/Which-programming-language-is-easier-to-learn-Python-or-C++
https://www.coursera.org/articles/how-long-does-it-take-to-learn-python-tips-for-learning#:~:text=In%20as%20little%20as%20three,and%20fix%20errors%20coding%20errors.
https://www.python.org/
https://www.python.org/about/gettingstarted/
https://docs.python.org/3/tutorial/index.html
https://www.python.org/downloads/
https://www.python.org/shell/
https://en.wikipedia.org/wiki/Python_(programming_language)
https://www.w3schools.com/python/python_intro.asp
https://python.plainenglish.io/mastering-python-the-10-most-difficult-concepts-and-how-to-learn-them-3973dd15ced4#:~:text=Understanding%20the%20complexities%20of%20OOP,and%20Network%20Programming%20in%20Python&text=These%20are%20arguably%20the%20most%20difficult%20concepts%20to%20learn%20with%20Python.
https://www.geeksforgeeks.org/python-programming-language-tutorial/
https://support.datacamp.com/hc/en-us/articles/360038816113-Is-Python-free#:~:text=Yes.,for%20free%20at%20python.org.
https://developers.google.com/edu/python/introduction#:~:text=Python%20is%20a%20dynamic%2C%20interpreted,checking%20of%20the%20source%20code.
https://www.geeksforgeeks.org/what-are-the-minimum-hardware-requirements-for-python-programming/#:~:text=Python%20Programming%20%2D%20FAQ's-,What%20are%20the%20minimum%20hardware%20requirements%20for%20Python%20programming%3F,simple%20scripting%20and%20small%20projects.
https://www.geeksforgeeks.org/python-programming-language-tutorial/
https://www.geeksforgeeks.org/python-programming-language-tutorial/
https://www.geeksforgeeks.org/introduction-to-python/
https://www.geeksforgeeks.org/python-quizzes/
https://www.geeksforgeeks.org/python-oops-concepts/
https://www.geeksforgeeks.org/python-string/
https://www.geeksforgeeks.org/python-programming-examples/
https://www.codecademy.com/catalog/language/python
https://www.w3schools.com/python/
https://www.w3schools.com/python/python_intro.asp
https://www.w3schools.com/python/python_syntax.asp
https://www.w3schools.com/python/python_exercises.asp
https://www.w3schools.com/python/python_lists.asp
https://docs.python.org/3/tutorial/index.html
https://docs.python.org/3/tutorial/appetite.html
https://docs.python.org/3/tutorial/introduction.html
https://docs.python.org/3/tutorial/classes.html
https://docs.python.org/3/tutorial/modules.html
https://en.wikipedia.org/wiki/Python_(programming_language)
https://en.wikipedia.org/wiki/Python_(programming_language)
Extracting absolute links from Google search results, as shown in the code snippet, is just the tip of the iceberg, and the example above only provided us a tiny subset of the info Google returned, namely the external links included in the page irrespective of where they are placed on the SERP. We also excluded embedded video results and didn't include link descriptions, and a plethora of other invaluable pieces of data buried in Google Search Results complex markup. Needless to say that in order to successfully scrape search engine results pages (SERPs), one needs (good) knowledge of the underlying HTML markup of the pages.
Moreover, to avoid being blocked by Google's anti-scraping measures, it's essential to utilize a web scraping API or, at the very least, employ headless browsers like PlayWright (as used in the example above) or Puppeteer (learn more about Puppeteer in our article). Additionally, IP rotation and proxy use are crucial to avoid being flagged and blocked. For projects that involve ongoing SERP extraction, it's vital to have a system in place to detect changes in the search result markup and quickly adapt to these changes to ensure uninterrupted data extraction.
This is where specialized scraping APIs like Ujeebu SERP API come in, allowing you to focus on extracting the data you need without worrying about overcoming anti-bot mechanisms and changing markup updates.
How to extract Google Search Results using Ujeebu SERP API
Now that we've covered how to extract links from a SERP, let's see how this can be achieved for production level projects. Below is an example of how to scrape a Google Search page without knowledge of its markup that's guaranteed to run at scale with close to zero chances of being blocked.
Note: here again we're going with Python, but the API can easily be used in a variety of other languages including and not limited to: Java, JavaScript/Node, Ruby, PHP, C#... Some examples can be found here.
# pip install requests
# use requests library
import requests
// API base URL
url = "https://api.ujeebu.com/serp"
// request options
params = {
'search': "python programming"
}
// request headers
headers = {
'ApiKey': "<Your Ujeebu API Key>"
}
// send request
response = requests.get(
url,
params=params,
headers=headers
)
print(response.text)Sample Output:
{
"knowledge_graph": {
"description": "Python is a high-level, general-purpose programming language. Its design philosophy emphasizes code readability with the use of significant indentation.\nPython is dynamically type-checked and garbage-collected.",
"designed_by": "Guido van Rossum",
"developer": "Python Software Foundation",
"filename_extensions": ".py,.pyw,.pyz,.pyi,.pyc,.pyd",
"first_appeared": "20 February 1991; 34 years ago",
"paradigm": "Multi-paradigm: object-oriented, procedural (imperative), functional, structured, reflective",
"stable_release": "3.13.2 \/ 4 February 2025; 36 days ago",
"title": "Python",
"type": "High-level programming language",
"typing_discipline": "duck, dynamic, strong; optional type annotations (since 3.5, but those hints are ignored, except with unofficial tools)",
"url": "https:\/\/en.wikipedia.org\/wiki\/Python_(programming_language)"
},
"metadata": {
"google_url": "https:\/\/www.google.com\/search?gl=US&hl=en&num=10&q=python+programming&sei=A4XSZ-3OILag5NoPv-ja0Ao",
"number_of_results": 581000000,
"query_displayed": "python programming",
"results_time": "0.28 seconds"
},
"organic_results": [
{
"cite": "https:\/\/www.python.org \u203a about \u203a gettingstarted",
"description": "An experienced programmer in any programming language (whatever it may be) can pick up Python very quickly. It's also easy for beginners to use and learn.",
"link": "https:\/\/www.python.org\/about\/gettingstarted\/",
"position": 1,
"site_name": "Python.org",
"title": "Python For Beginners"
},
{
"cite": "https:\/\/www.python.org",
"description": "Python is a programming language that lets you work quickly and integrate systems more effectively. Learn More",
"link": "https:\/\/www.python.org\/",
"position": 2,
"site_name": "Python.org",
"title": "Welcome to Python.org"
},
{
"cite": "https:\/\/www.w3schools.com \u203a python \u203a python_intro",
"description": "Python is a popular programming language. It was created by Guido van Rossum, and released in 1991. It is used for:",
"link": "https:\/\/www.w3schools.com\/python\/python_intro.asp",
"position": 3,
"site_name": "W3Schools",
"title": "Introduction to Python"
},
{
"cite": "https:\/\/en.wikipedia.org \u203a wiki \u203a Python_(programming...",
"link": "https:\/\/en.wikipedia.org\/wiki\/Python_(programming_language)",
"position": 4,
"site_name": "Wikipedia",
"title": "Python (programming language)"
},
{
"cite": "https:\/\/www.geeksforgeeks.org \u203a python-programming-...",
"link": "https:\/\/www.geeksforgeeks.org\/python-programming-language-tutorial\/",
"position": 5,
"site_name": "GeeksforGeeks",
"title": "Python Tutorial | Learn Python Programming Language"
},
{
"cite": "https:\/\/www.coursera.org \u203a ... \u203a Software Development",
"description": "Install Python and write your first program. Describe the basics of the Python programming language. Use variables to store, retrieve and calculate information.",
"link": "https:\/\/www.coursera.org\/learn\/python",
"position": 6,
"site_name": "Coursera",
"title": "Programming for Everybody (Getting Started with Python)"
},
{
"cite": "https:\/\/en.wikibooks.org \u203a wiki \u203a Python_Programming",
"description": "This book describes Python, an open-source general-purpose interpreted programming language available for the most popular operating systems.",
"link": "https:\/\/en.wikibooks.org\/wiki\/Python_Programming",
"position": 7,
"site_name": "Wikibooks",
"title": "Python Programming - Wikibooks, open books for an ..."
},
{
"cite": "https:\/\/www.codecademy.com \u203a catalog \u203a language \u203a p...",
"description": "Learn how to code in Python, design and access databases, create interactive web applications, and share your apps with the world.",
"link": "https:\/\/www.codecademy.com\/catalog\/language\/python",
"position": 8,
"site_name": "Codecademy",
"title": "Best Python Courses + Tutorials"
}
],
"pagination": {
"google": {
"current": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&",
"next": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=20&tbm=&",
"other_pages": {
"3": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=30&tbm=&",
"4": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=40&tbm=&",
"5": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=50&tbm=&",
"6": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=60&tbm=&",
"7": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=70&tbm=&",
"8": "https:\/\/google.com\/search?gl=US&hl=en&num=10&q=python+programming&start=80&tbm=&"
}
},
"api": {
"current": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=1&results_count=10&search=python+programming&",
"next": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=2&results_count=10&search=python+programming&",
"other_pages": {
"3": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=3&results_count=10&search=python+programming&",
"4": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=4&results_count=10&search=python+programming&",
"5": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=5&results_count=10&search=python+programming&",
"6": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=6&results_count=10&search=python+programming&",
"7": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=7&results_count=10&search=python+programming&",
"8": "https:\/\/api.ujeebu.com\/serp?device=desktop&lang=en&location=US&page=8&results_count=10&search=python+programming&"
}
}
},
"related_questions": [
"What is Python programming used for?",
"Is it difficult to learn Python?",
"What are the 33 words in Python?",
"Can I learn Python in 3 months?",
"Hardest part",
"\u2026",
"What is the hardest part of Python?",
"Basics",
"\u2026",
"Basics of Python",
"Free",
"\u2026",
"Is Python free?",
"Language Definition",
"\u2026",
"What is Python, and how does it work?",
"Basic requirements",
"\u2026",
"Basic requirements of python"
],
"top_stories": null,
"videos": [
{
"author": "Programming with Mosh",
"date": "1 month ago",
"link": "https:\/\/m.youtube.com\/watch?v=K5KVEU3aaeQ&t=614",
"provider": "YouTube",
"title": "Python Full Course for Beginners [2025]"
},
{
"author": "Bro Code",
"date": "Aug 20, 2024",
"link": "https:\/\/www.youtube.com\/watch?v=ix9cRaBkVe0",
"provider": "YouTube",
"title": "Python Full Course for free \ud83d\udc0d (2024)"
},
{
"author": "freeCodeCamp.org",
"date": "Aug 9, 2022",
"link": "https:\/\/www.youtube.com\/watch?v=eWRfhZUzrAc",
"provider": "YouTube",
"title": "Python for Beginners \u2013 Full Course [Programming Tutorial]"
},
{
"author": "Programming with Mosh",
"date": "Sep 10, 2024",
"link": "https:\/\/www.youtube.com\/watch?v=yVl_G-F7m8c",
"provider": "YouTube",
"title": "Python Projects for Beginners \u2013 Master Problem-Solving! \ud83d\ude80"
}
]
}As you can see, using a few lines of code, we were able to get a structured object including all the info on the page. Please also note that besides being able to scrape text search results from Google, you can use the same API to scrape Google Images, Google News, Google Maps and Google Videos the same way, simply by changing the search_type parameter.
Key Takeaways
Scraping Google search results opens up a gold mine of valuable insights for all types of businesses and researchers across a variety of fields. However, it's a complex process that requires careful consideration of technical, ethical, and legal aspects. As search engine technologies evolve, staying informed about best practices and legal considerations will be crucial for anyone engaged in SERP data extraction.
While DIY scraping is possible, it's worth noting that specialized tools like Ujeebu offer an easier, more streamlined approach. Ujeebu's Google SERP API provides a ready-to-use solution that handles all the complexities discussed in this guide, allowing users to focus on data analysis rather than the scraping implementation. Sign up today and get 200 free searches, no credit card required.
Frequently asked questions
- Is it legal to scrape Google search results?
Web scraping itself is not illegal, but it's important to comply with Google's Terms of Service and robots.txt file. Always use the data responsibly and ethically. - How do I scrape Google search results?
You can scrape Google search results using various methods, including custom scrapers and specialized tools like Ujeebu SERP API. - Is there a limit to Google search scraping?
Google doesn't provide official limits, but excessive scraping can lead to IP blocks. Using a service like Ujeebu helps manage these limitations effectively. - What tools can I use to scrape Google search results?
You can use custom scripts with libraries like Beautiful Soup or Scrapy, headless browsers like Puppeteer, or specialized tools like Ujeebu's Google SERP API. - Can I use scraped Google search results for commercial purposes?
While you can use the insights gained from scraped data, it's important to review Google's Terms of Service and consult legal advice to ensure compliance with applicable laws and regulations.
