

Data is the new gold. With the rise of AI and machine learning applications, this statement has never bee
n more accurate. To extract the value from this data goldmine, businesses need robust tools to mine it, process it, and prepare it for actionable insights. Being data-conscious empowers organizations to move beyond intuition, leveraging concrete evidence and thorough analysis to inform their decisions. This approach enhances understanding of market dynamics, customer behaviors, and operational efficiencies, leading to optimized strategies, reduced risks, and the ability to seize new opportunities with confidence.
Web scraping plays a crucial role in this ecosystem by enabling the collection of vast amounts of data from the web, providing real-time information and competitive intelligence. Python, combined with the Beautiful Soup library, provides an excellent toolkit for scraping web content efficiently. This guide will walk you through the process of using Python and Beautiful Soup to scrape data from websites. But first let’s get foundational.
What is Web Scraping?
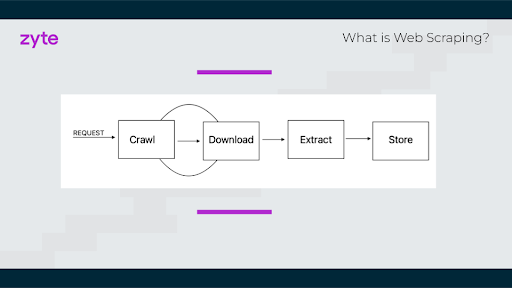
Web scraping is the automated process of extracting data from websites. It's essentially like copying information from a webpage manually, but it's done programmatically, allowing for large amounts of data to be collected quickly and efficiently.
Web Scraping has two parts to it-
Sending HTTP GET Requests:
Using libraries like requests in Python, you can send a GET request to a website’s server. The server then responds with the HTML content of the webpage.
HTML Parsing:
After retrieving the HTML content, you can use libraries like BeautifulSoup to parse the document. Parsing converts the HTML into a structured format that can be manipulated and used to extract specific data points.
However, there are multiple steps involved in Web Scraping.
Steps Involved in Web Scraping
Step 1: Identify Your Target
- Determine the website from which you want to scrape data.
- Check if it provides APIs(Application Programming Interface) to extract the information you need.
- Ensure the website allows web scraping by checking its terms of service and robots.txt file.
Step 2: Inspect the Website Structure
- Use a browser's developer tools (F12 or Ctrl + Shift + I) to view the website's HTML code.
- Understand how the data you want is organized on the webpage. If it is loaded dynamically through JavaScript, you would need to integrate Headless browser libraries like Playwright, Puppeteer, or Selenium.
Step 3: Crawl the website.
- Navigate through multiple web pages to find the data you need.
- Use a web crawler or a spider to traverse the website's pages.
Step 4: Download
- Download the HTML content of the web pages using a library like Requests in Python.
Step 5: Extract
- Extract the specific data points from the HTML content using parsing techniques.
- Use a library like Beautiful Soup in Python to parse the HTML code and pinpoint the data elements.
Step 6: Store
Save the extracted data into a structured format like:
- CSV (comma-separated values)
- JSON (JavaScript Object Notation)
- Database
These formats allow for easy import into spreadsheets or databases for further analysis.
Following these steps, you can extract data from websites using web scraping techniques.
Why use Python for Web Scraping?
Python is a popular choice for web scraping due to its ease of use, extensive libraries, and flexibility. Its simplicity makes it easy to learn and focus on the task at hand, while libraries like Beautiful Soup, Requests, Scrapy, and Selenium provide powerful tools for extracting data from websites.
With Python, you can quickly and efficiently scrape websites, and its cross-platform compatibility means you can run your scripts on any platform. Plus, Python's large community ensures there are plenty of resources available to help you overcome any obstacles. Whether you're a beginner or an experienced developer, Python is an ideal language for web scraping.
Web scraping with Python using Beautiful Soup
Let’s follow the above steps in web scraping using the BeautifulSoup and Requests library.
Before that, let’s install the Beautiful Soup and Requests library using pip:
pip install beautifulsoup4 requests
Step 1: Identify Your Target Website/Websites
We will use `https://quotes.toscrape.com/` as a target website for this blog.
Step 2: Inspect the Web Page
- Open the web page you want to scrape in a browser.
- Inspect the HTML structure of the page using the browser's developer tools (F12 or Ctrl + Shift + I).
- Identify the HTML elements that contain the data you want to extract. In this tutorial, we will extract the quotes and their author names.

Step 3: Send an HTTP Request to the Web Page
- Use the Requests library to send an HTTP request to the web page:
import requests
url='https://quotes.toscrape.com/'
response = requests.get(url)
Step 4: Parse the HTML Content
- Use Beautiful Soup to parse the HTML content of the web page:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
Step 5: Find the Desired HTML Elements
- Use Beautiful Soup's methods (e.g., find, find_all) to locate the HTML elements that contain the data you want to extract:
quotes = soup.find_all('div', {'class': 'quote'})
Step 6: Extract the Data
- Extract the data from the HTML elements using Beautiful Soup's methods
quotes_data = []
for quote in quotes:
author = quote.find('small', {'class': 'author'}).text
quote_text = quote.find('span', {'class': 'text'}).text
quotes_data.append({
'quote': quote_text,
'author': author
})Step 7: Store the Data
- Store the extracted data in a format of your choice (e.g., CSV, JSON, database)
with open('quotes.json', 'w') as f:
json.dump(quotes_data, f, indent=4)
print("Data stored in quotes.json")
The final code looks like this
import json
url = 'http://quotes.toscrape.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
quotes = soup.find_all('div', {'class': 'quote'})
quotes_data = []
for quote in quotes:
author = quote.find('small', {'class': 'author'}).text
quote_text = quote.find('span', {'class': 'text'}).text
quotes_data.append({
'quote': quote_text,
'author': author
})
with open('quotes.json', 'w') as f:
json.dump(quotes_data, f, indent=4)
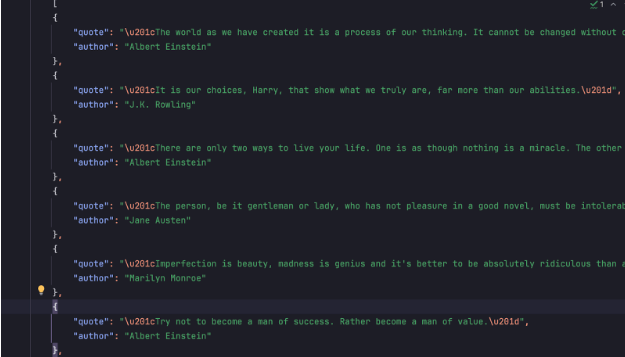
print("Data stored in quotes.json")The output looks like this-
Drawbacks and limitations of using BeautifulSoup
Although BeautifulSoup provides an excellent foundation to start web scraping projects and even for basic inspecting, and testing the suitable selectors to start working with. It starts falling short on multiple fronts when you scale your projects. Here are some of the limitations you should be aware of.
BeautifulSoup is not suitable for Large-Scale Web Scraping because
- It only parses the initial HTML response and does not execute JavaScript code. This means it cannot extract content that is generated dynamically by JavaScript.
2. Have built-in support for handling anti-scraping measures such as CAPTCHAs, rate limiting, or IP blocking.
3. It is not thread-safe, which means it's not suitable for use in multi-threaded or multi-process environments.
4. It can be slow, particularly when handling large documents or complex HTML structures. This is due to the need to parse the entire document and construct a tree-like data structure in memory. As a result, for large-scale web scraping involving numerous pages, BeautifulSoup can become both slow and memory-intensive
By following these steps, you can set up a basic web scraping script to gather data from a target website. Libraries like Beautiful Soup, makes web scraping manageable and efficient. However, it's important to be aware of the limitations of using Beautiful Soup, especially when scaling up your projects. Challenges such as handling JavaScript-generated content, anti-scraping measures, and performance issues with large-scale scraping need to be addressed.
For those looking to scale their web scraping efforts without getting bogged down by the complexities of handling proxies, JavaScript execution, and other technical hurdles, consider using Ujeebu. Ujeebu offers a robust API that simplifies the web scraping process, managing all the behind-the-scenes difficulties for you.
Frequently Asked Questions
- How long does it take to learn web scraping with Python?
The time it takes to learn web scraping with Python depends on several factors, such as:
- Your prior experience with Python and programming in general.
- The complexity of the web scraping tasks you want to accomplish.
- The amount of time you dedicate to learning and practicing.
However, with consistent effort, you can learn the basics of web scraping with Python in a few weeks to a few months. Here's a rough estimate of the time it may take to reach different levels of proficiency:
- Basic understanding of web scraping concepts and tools: 1-2 weeks
- Ability to scrape simple websites: 2-4 weeks
- Ability to scrape complex websites with JavaScript rendering: 2-6 months
- Mastery of advanced web scraping techniques and tools: 6-12 months
2. What are the benefits of using Beautiful Soup to scrape web data?
Beautiful Soup is a popular Python library for web scraping, and its benefits include:
- Easy to learn and use, even for those without extensive programming experience
- Supports various parsing engines, including lxml and html5lib
- Allows for easy navigation and searching of the parsed document tree
- Supports handling of broken or malformed HTML documents
- Extensive community support and documentation
3. What is the best way to web scrape in Python?
The best way to web scrape in Python involves:
- Using a robust and efficient HTTP client library like requests or urllib or a framework like Scrapy.
- Employing a powerful HTML parsing library like Beautiful Soup or lxml.
- Headless Browser capabilities to handle data within javascript.
- Handling anti-scraping measures like CAPTCHAs and rate-limiting.
- Storing scraped data in a structured format like CSV, JSON, or a database.
- Implementing error handling and logging mechanisms.
- Monitor spiders with tools like Spidermon.
- Respecting website terms of service and robots.txt files.
4. What is the purpose of BeautifulSoup in Python?
Beautiful Soup is a Python library used for web scraping, specifically for parsing and navigating HTML and XML documents. Its primary purpose is to:
- Parse HTML and XML documents into a tree-like data structure
- Allow for easy navigation and searching of the parsed document tree
- Extract specific data from the document, such as text, links, or images
5. What is the Python library for scraping data?
There are several Python libraries for web scraping, including:
- Beautiful Soup (BS4)
- Scrapy
- Selenium, Playwright or Puppeteer.
- Requests
- LXML
- PyQuery
Each library has its strengths and weaknesses, and the choice of the library depends on the specific web scraping task at hand.
6. Can Python scrape a website?
Yes, Python can be used to scrape websites. Python's versatility, combined with its extensive libraries and tools, make it an ideal language for web scraping. With Python, you can:
- Send HTTP requests to websites using libraries like requests or urllib
- Parse HTML and XML documents using libraries like Beautiful Soup or lxml
- Extract dynamic data from websites using libraries like Selenium, Playwright or Puppeteer.
- Store scraped data in structured formats like CSV, JSON, or databases.
However, it's essential to respect website terms of service and robots.txt files and to avoid scraping websites that explicitly prohibit web scraping.
