

Web data scraping has become indispensable for organizations seeking actionable insights from the vast expanse of online data. However, manual workflows often struggle with inefficiencies, scalability limitations, and human error. By integrating Ujeebu API with Robotic Process Automation (RPA), teams can automate repetitive tasks, enhance accuracy, and scale operations effortlessly. This article explores how merging these technologies creates a robust, future-proof solution for developers, data engineers, and business leaders alike.
The Synergy Between RPA and Ujeebu API
Robotic Process Automation (RPA) refers to software robots that mimic human interactions with digital systems. These bots excel at automating rule-based tasks such as data entry, validation, and report generation. When paired with Ujeebu API—a tool designed to bypass CAPTCHAs, JavaScript rendering, and IP blocks—RPA extends its capabilities to manage end-to-end web scraping workflows.
Traditional RPA platforms like UiPath and Automation Anywhere are ideal for complex enterprise workflows, while no-code tools like Zapier and Make (formerly Integromat) offer lightweight automation for smaller teams. For instance, Zapier can connect Ujeebu API to CRM systems like Salesforce, automatically enriching lead data without manual intervention.
The benefits of this integration are multifaceted. RPA eliminates the tedium of repetitive tasks, allowing developers to focus on strategic analysis. According to McKinsey, automation can reduce operational costs by 30–50%, while Ujeebu API ensures reliable data extraction from even the most complex websites. Together, they enable businesses to process thousands of data points daily with minimal oversight.
Introducing Ujeebu's Web Scraper API
Ujeebu is a web scraping API designed to simplify data extraction from any web page. In an RPA + API scenario, Ujeebu serves as the "web data extractor" that your RPA bot can call whenever it needs to scrape information from a site. What makes Ujeebu particularly powerful for this use case?
- Headless Browser Rendering: Ujeebu uses real headless Chrome browsers on the backend to load pages. This means it can execute JavaScript and render dynamic content that simpler HTTP requests would miss. Your bot doesn't have to struggle with waiting for elements or simulating scrolls – Ujeebu does it and can return the fully loaded page HTML or even a screenshot.
- Built-in Proxy Management: Websites often block scrapers by IP or detect bots. Ujeebu's API automatically routes requests through rotating proxies, including residential proxies with geo-targeting, to reduce the chance of getting blocked. This is all handled for you – a huge relief compared to managing proxy lists in your RPA workflow.
- Auto-Retry and Anti-bot Evasion: The API is built to handle failures gracefully (retrying on timeouts, etc.) so your RPA doesn't stall on these hurdles. Essentially, Ujeebu's motto of "Fewer Blocks, Better Data" holds true – it's optimized to get the data successfully where an RPA bot might get stuck.
- Targeted Data Extraction: Perhaps most useful is Ujeebu's ability to return structured data. You can send an API request with extraction rules (CSS selectors or JSON paths for the data you want), and Ujeebu will return just those fields in JSON format. For example, if you need the title and price from a product page, you can specify those selectors; the API will return:
{"title": "Sample Product", "price": "$19.99"}. This eliminates the need for your RPA bot to parse HTML or screen text – the data comes clean and ready to use. - Scalability and Speed: Because Ujeebu operates via API, it can be called in parallel or in rapid succession. RPA workflows that needed to open a browser and scrape page-by-page can now fire off multiple API calls (or loop through calls faster than a UI approach). The heavy lifting is offloaded to Ujeebu's cloud service, which is built for scraping at scale, so your automation can handle larger volumes of pages in less time.
In summary, Ujeebu turns any website into a more easily consumable data source for your automations – effectively a web scraping-as-a-service that complements RPA.
Benefits of Integrating Ujeebu API into RPA Workflows
By integrating Ujeebu with RPA, you combine the strengths of both approaches. Here are some key benefits and how they address common pain points:
Reliability on Dynamic Websites: RPA bots often struggle with dynamic content (like content that appears after scrolling or clicking "Load more"). With the Scrape API, the bot can request the page via API with js=true (JavaScript enabled), and by using custom_js which allows the injection of JavaScript commands, or, if a scroll behavior is needed, scroll_down along with scroll_wait. Ujeebu will handle all the scrolling or clicking behind the scenes. The RPA simply waits for the JSON or HTML response – no more broken selectors because an element wasn't loaded.
Lower Maintenance: If a website's layout changes, an RPA script might crash whereas Ujeebu's extraction rules can be adjusted quickly or might even tolerate minor HTML changes better. Maintaining a few extraction rule definitions is often simpler than reworking an entire click-by-click RPA script. This means less upkeep work for your team when websites update their design.
Speed and Efficiency: Suppose your process needs to scrape 100 product pages. An RPA bot might take several minutes, opening a browser for each page sequentially. With the API approach, the bot could make multiple calls concurrently or in a tight loop, retrieving data in seconds. This hybrid can drastically reduce execution time for data-intensive tasks.
Complex Navigation Made Easy: RPA is good at logging into accounts or navigating multi-step forms (things an API alone might not easily do without scripting). You can use RPA for those interactive steps – e.g., log into a dashboard – then use our Scrape API to extract the data once at the final page. This way, you're using each tool where it’s strongest. The result is a more robust automation that can handle logins, navigations (via RPA), and data extraction (via API).
Compliance and Security: Instead of embedding third-party scraping scripts in your RPA or using headless browsers on employee desktops (which can pose security risks), Ujeebu offers a controlled, server-side approach. All web requests go through a secure API. This can be easier to monitor and align with IT policies, especially when dealing with sensitive data, since the data extraction is encapsulated in a service call.
How to Implement Ujeebu API in an RPA Workflow
Integrating Ujeebu into your RPA process is straightforward. Most modern RPA platforms (UiPath, Automation Anywhere, Blue Prism, etc.) have the ability to make web service calls or HTTP requests as part of a workflow. You'll typically follow the steps illustrated and detailed below:
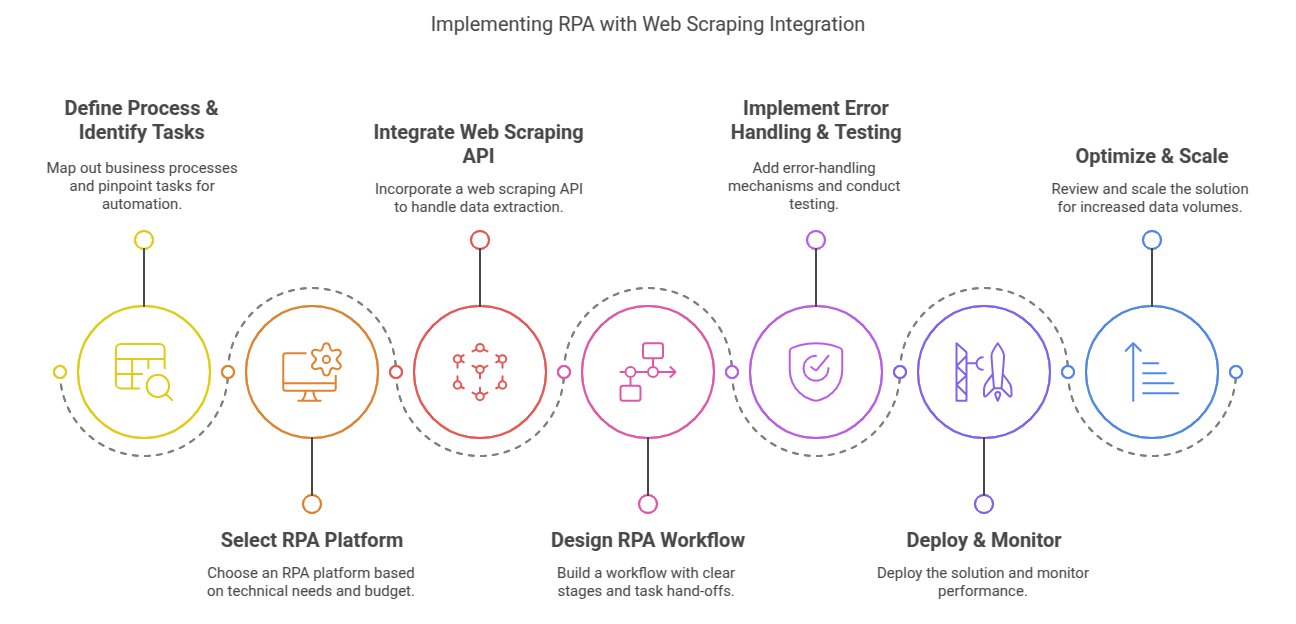
1. Get API Access: Sign up for an account here (we offer a free trial with API credits to get started). Obtain your API key from the dashboard.
2. Design the RPA Flow: In your RPA tool, instead of creating a complex web-scraping sequence, use an HTTP Request activity (or equivalent) at the point where data needs to be scraped.
3. Configure the API Call: Set the request URL to Ujeebu’s endpoint, e.g. https://api.ujeebu.com/scrape. Include required parameters such as the target page URL and your API key (often passed in headers or as a query param). For example, you might set up a GET request to:
https://api.ujeebu.com/scrape?url=https://example.com&page=1&js=true&response_type=json
(The above would fetch the page and return a JSON response after rendering JS on the page.)
For a more complex extraction, you would send a POST request with a JSON body defining extract_rules. For instance, to extract a page's title and price, your RPA can POST something like:
{
"url": "https://example.com/product/123",
"js": true,
"response_type": "json",
"extract_rules": {
"title": { "selector": "h1.product-title", "type": "text" },
"price": { "selector": ".price-value", "type": "text" }
}
}
Ujeebu will respond with a JSON containing just those fields. In your RPA workflow, you then parse the JSON (RPA tools have JSON parsing capabilities or you can treat it like a dictionary) and use the data (e.g. input it into another system, or save it to a file/database).
4. Error Handling and Delays: Incorporate checks in your RPA flow for the API response. If the response indicates an error (network issue, or Ujeebu returns an error code), your bot can retry the call or take a fallback action. In many cases, Ujeebu's built-in retry logic will already have attempted the fetch, so you typically only need to handle a final failure scenario. Also consider adding a small delay or respecting any rate limits (if scraping very rapidly). Although Ujeebu is built for scale, it's good practice to pace extremely large bursts or use concurrency thoughtfully to avoid hitting any limits of the API or the target site.
5. Continue the Workflow: Once data is obtained, the RPA can proceed with the rest of the process (perhaps inputting that data elsewhere, or looping to the next URL). Essentially, the RPA workflow "calls" Ujeebu and waits, then resumes with fresh data, much like calling a subroutine and getting a result.
This implementation approach means your RPA developer doesn't need to write complex scraping code – they just configure API calls. The learning curve for using Ujeebu's API is minimal, especially with provided documentation and examples. If you can use REST APIs in your RPA platform, you can integrate Ujeebu.
Real-World Use Case Example
To illustrate, imagine a price monitoring scenario for an e-commerce company: They have an RPA bot that logs into several competitor websites (which don't provide official APIs) to collect product prices daily. Originally, the bot used to navigate each site's pages and scrape prices via screen automation – a brittle process often breaking when websites changed. By integrating Ujeebu, the company redesigned the bot to do what it does best (login, navigate to the correct page for each product) and then hand off the data extraction to the API. The bot passes each product page URL to Ujeebu's /scrape endpoint with extraction rules for the product name and price. Ujeebu returns clean data which the bot records into a spreadsheet and moves on. The result? The price collection process runs in half the time it used to, because Ujeebu fetches data faster than the old click-and-wait method. Maintenance went down too; when a competitor's site changed its layout, the team simply updated the CSS selector in the Ujeebu extract_rules, instead of reworking the entire RPA click sequence. This hybrid approach freed the automation team from constant firefighting and ensured the business has up-to-date pricing info every morning.
Another example is in the finance industry: consider an analyst who needs to gather financial data from various websites (stock info, news, interest rates) as part of a report generation. An RPA bot can be scheduled to run nightly, use Ujeebu API calls to scrape the latest figures from multiple sites, and then feed that data into the report template or database. What used to require multiple fragile scrapers or manual copy-paste is now a hands-off automated pipeline. Such stories are increasingly common as companies realize they don't have to choose between RPA or APIs – they can use both together to great effect.
Best Practices & Tips
When using RPA and Ujeebu in tandem, here are a few best practices to keep in mind for optimal results:
Optimize Extraction Rules: If you only need part of the page, use extract_rules to limit the data. This reduces payload size and speeds up post-processing. It also makes your integration more resilient to site changes, since you're focusing on specific elements.
Secure your API Keys: Store the Ujeebu API key securely in your RPA tool (most have secure credential storage). Do not hard-code it in plain text within scripts. This protects you in case someone unauthorized accesses the RPA project files.
Monitor Usage and Errors: Ujeebu provides response codes and even an usage endpoint to check your API consumption. Have your bot log the outcomes of each API call (success or error). This will help in troubleshooting if something goes wrong. For instance, if a particular site started showing CAPTCHA challenges suddenly (which Ujeebu can often handle by integration with anti-captcha services), you'd see error patterns and can adjust accordingly (like adding a delay).
Leverage Concurrency Carefully: If your RPA platform and Ujeebu plan allow, you can call multiple scrape requests in parallel (for example, launching multiple bot instances or threads). This can vastly speed up data collection. Just be mindful of the target websites' load. Hitting a site with hundreds of requests per second, even via API, could get you blocked. Ujeebu's rotating proxies help mitigate this, but it's wise to consider a reasonable throughput or use a queue mechanism for very large jobs.
Stay Within Legal and Ethical Bounds: As with any web scraping, ensure the data you're scraping is not behind logins you shouldn’t have access to, and that you respect the target site's terms of service or robots.txt where applicable. Ujeebu is a tool that can scrape virtually anything technically, but it's up to your organization to use it responsibly. The combination of RPA (which might use credentials to log in) and a powerful scraper means you should double-check compliance especially in regulated industries.
Conclusion: The Future of RPA + API Integration
By integrating Ujeebu's scraping API into RPA workflows, businesses get the best of both worlds: the workflow orchestration and easy integration of RPA, together with the robustness and scalability of a dedicated web data extraction service. This approach transforms web scraping from a fragile, time-consuming script into a reliable API call. Teams can focus on leveraging the data, not struggling to collect it.
As RPA continues to grow and evolve (with trends pointing to more intelligent automation and use of AI), pairing it with flexible APIs will be a standard best practice for extensibility. If you're currently using RPA and finding web data gathering to be a pain point, it's a great time to explore an integration like this.
Next Steps – Try It Yourself: Ready to supercharge your RPA bots with effortless web scraping? Sign up for a free Ujeebu account and follow the documentation to set up your first API call. In minutes, your RPA bot could be pulling data from the web with new efficiency and accuracy. Don't let your automation be held back by web scraping challenges – combine RPA with Ujeebu's API and watch your data acquisition process become streamlined and scalable.
Unlock the full potential of your RPA projects by integrating the right tools. Here's to building smarter, more resilient automations with the power of RPA+API integration!
