

When it comes to scraping e-commerce data, Amazon is often the first name that springs to mind. With over 600 million products listed across more than 50 countries, Amazon's product data is a goldmine of information that can help propel your business ahead of the competition.
Although scraping publicly available data is legal, Amazon often takes measures to prevent it. Scraping Amazon, especially while bypassing its anti-scraping mechanisms, is no small feat. In this guide, we’ll show you how to build an Amazon scraper capable of extracting product data, without getting blocked.
We will start with a basic tutorial with two Python libraries - Requests and BeautifulSoup. We'll also share valuable tips, tools, and techniques to help you navigate complexities such as IP rate limitations and potential bans, which can hinder your scraping efforts to successfully scrape Amazon product data. We'll cover a range of strategies to ensure your scraper remains undetected and efficient.
By the end of this guide, we hope that you'll have a solid understanding of how to build an Amazon scraper that can extract product data reliably and effectively. But first, let’s go through the main use cases for scraping Amazon data in a business context.
Why Scrape Amazon Product Data
Scraping Amazon data is pretty valuable for businesses looking to gain a competitive edge in the e-commerce landscape and there are many use cases. One of the top use cases is the ability to conduct competitive pricing analysis. By monitoring the prices of competitors' products in real time, companies can quickly adjust their pricing strategies to remain competitive and attract more customers.
In addition to pricing analysis, Amazon data scraping supports comprehensive market research. By analyzing product categories, bestsellers, and trending items, businesses can gain valuable insights into consumer preferences and buying patterns. This information is crucial for making informed decisions about product development, allowing companies to create or improve products that align with customer demands. Customer sentiment analysis, gleaned from product reviews and ratings, offers additional benefits by providing direct feedback from consumers. This feedback helps businesses refine their products and customer service approaches, enhancing overall customer satisfaction.
Another key benefit of Amazon data scraping is its role in inventory management. By monitoring stock levels and sales velocity, businesses can optimize their inventory, reducing the risk of overstocking or running out of popular items. This data-driven approach helps companies maintain a healthy balance between supply and demand, ultimately improving profitability.
From competitive pricing and market research to inventory management and customer sentiment analysis, the insights gained from Amazon data can give companies a significant advantage in the highly competitive e-commerce market.
Now, let’s see how we can get the Amazon Product data, one step at a time.
How To Scrape Amazon Product Data
Fundamental Requirements: Let’s start with the foundational tech stack required for scraping Amazon, defining the scope of work, and extracting key product information. Make sure you have Python installed on your system before proceeding. We will install two libraries, BeautifulSoup and Requests.
BeautifulSoup: This library is used for parsing HTML and XML documents. It creates parse trees from page source code that can be used to extract data easily.
Requests: This library allows you to send HTTP requests using Python. It simplifies the process of making requests and handling responses.
To install these two libraries, run the following command in your terminal.
pip install beautifulsoup4 requestsBest Practice Tip
Defining the scope of your project is one of the most underrated steps, but it is crucial for the success of your scraping project. Start with a clear purpose statement:
- What data do you need?
- What will you do with this data?
While it may not seem important for a small proof of concept (POC), having a well-defined problem statement can save a lot of money, time, and resources as your project scales. Avoid hoarding unnecessary data. Instead, begin any project with a mission statement to stay focused and efficient.
Scope of this Guide
In this guide, we will:
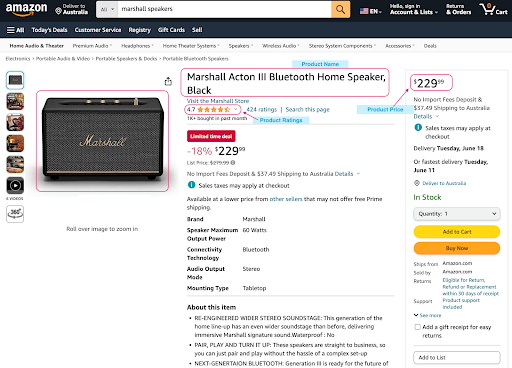
- Scrape the product page from the following URL: Marshall Acton III Bluetooth Home Speaker
- Extract the following information:
-Product Name
-Price
-Rating
-Description

3. Explore various strategies to navigate antiban measures.
Step-by-Step Guide to Scrape Amazon Data
- Create a folder `scraping_amazon` and an `amazonScraper.py` file in that folder.
- In the `amazonScraper.py` file, paste the following code:
import requests
url="https://www.amazon.com/Marshall-Acton-Bluetooth-Speaker-Black/dp/B0BC27MM5Z"
html = requests.get(url)
print(html.text)You will most likely be blocked. Try it out, you might get lucky :) This is because of various bot detection methods used by Amazon to limit loading their servers from requests by the scraping bots.
3. A way you can bypass getting blocked is by mimicking the request coming from a real user and not a bot. This can be done using user-agent.
Let’s add `User-Agent` to this code and request again.
a. You can get your `User-Agent` from this website- http://whatmyuseragent.com
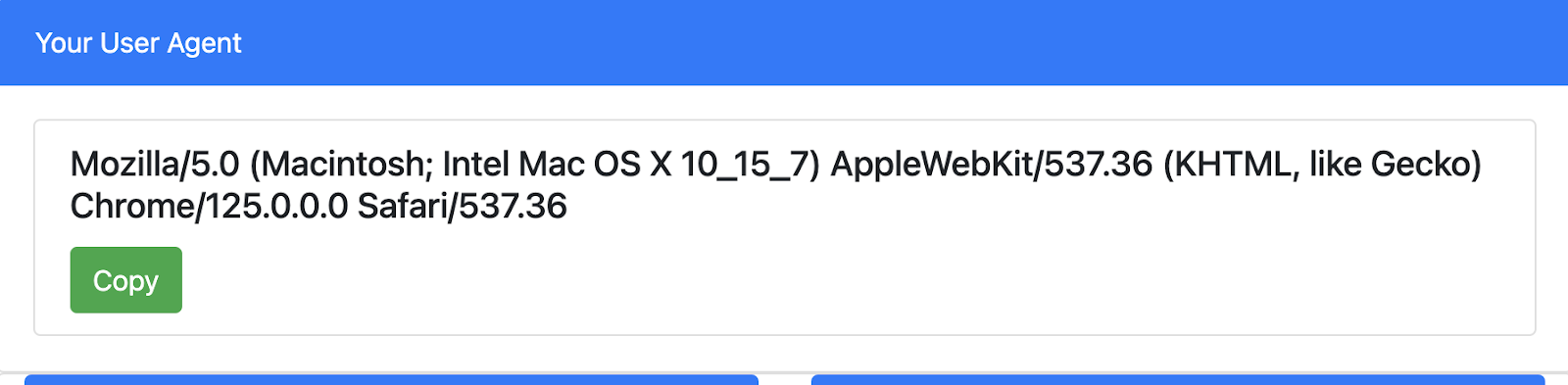
b. Add headers to the above code, `User-Agent` to the above code
import requests
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}
url = "https://www.amazon.com/Marshall-Acton-Bluetooth-Speaker-Black/dp/B0BC27MM5Z"
html = requests.get(url, headers=HEADERS)
print(html.text)
You should be able to get a response after this. If not, you try rotating user agents or rotating proxies. Now let’s get onto extracting the data from the html. We will use the BeautifulSoup library to extract the product name, price, ratings and description.
4. We will import the Beautifulsoup library and add this line to the code.
soup = BeautifulSoup(html.text, "html.parser")- html.text: This is a string containing the HTML content of a web page, likely obtained from a web scraping or HTTP request.
- html.parser: This is the parser used by BeautifulSoup to parse the HTML content. There are other parsers available, such as lxml and xml, but html.parser is the default and most commonly used.
The BeautifulSoup constructor takes two arguments: the HTML content to parse (response.text) and the parser to use (html.parser). The resulting object, soup, is a parsed representation of the HTML document.
5. For the extraction code, you need exact information about the html tags that hold the data that you need. You can do so by following these steps.
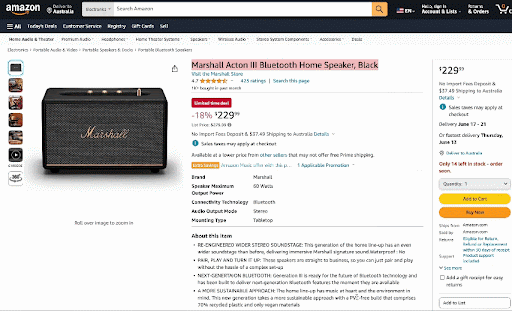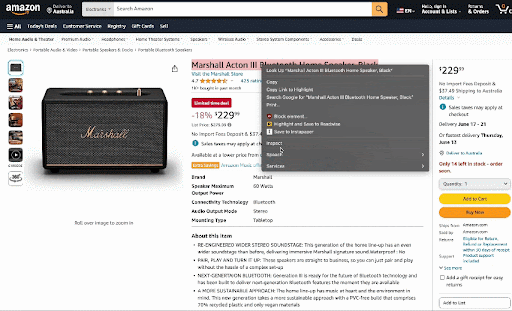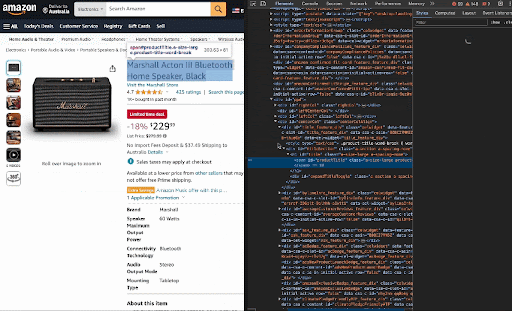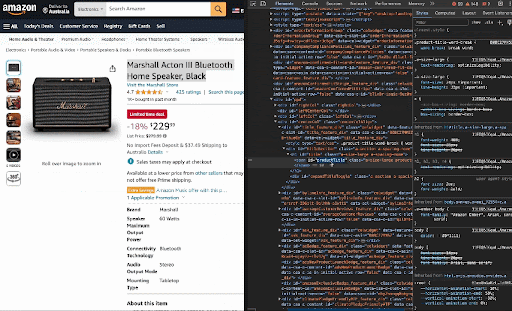
a. Go to the product page- Marshall Acton III Bluetooth Home Speaker
b. Right-click on the element you want to extract and select inspect. I am adding a GIF for the product title below.
c. Add this line to the code:
title = soup.find('span', {'id':"productTitle"}).getText().strip()
- soup.find(): This method searches the parsed HTML document for a specific element. In this case, it's looking for a <span> element with an id attribute equal to "productTitle".
- {'id':"productTitle"}: This is a dictionary specifying the attributes to search for. In this case, it's looking for an element with an id attribute equal to "productTitle".
- .getText(): This method extracts the text content of the found element.
- .strip(): This method removes any leading or trailing whitespace from the extracted text.
d. Repeat the steps b and c for the product price, description, and ratings. Add the following lines to the code:
price = soup.find('span',{'class':"aok-offscreen"}).getText().strip().split(" ")[0]
rating = soup.find('span', {'class':"a-size-base a-color-base"}).getText().strip()
description = soup.find('div', {'id':"productDescription"}).getText().strip()
print(f"Title: {title}, Price: {price}, Rating: {rating}, Description: {description}")This is what the final code looks like:
import requests
from bs4 import BeautifulSoup
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'
}
url = "https://www.amazon.com/Marshall-Acton-Bluetooth-Speaker-Black/dp/B0BC27MM5Z"
html = requests.get(url, headers=HEADERS)
print(html.text)
soup = BeautifulSoup(html.text,"html.parser")
title = soup.find('span', {'id':"productTitle"}).getText()
price = soup.find('span', {'class':"aok-offscreen"}).getText().strip().split(" ")[0]
rating = soup.find('span', {'class':"a-size-base a-color-base"}).getText().strip()
description = soup.find('div', {'id':"productDescription"}).getText().strip()
print(f"Title: {title}, Price: {price}, Rating: {rating}, Description: {description}")However, as you plan to scale your Amazon scraping project to extract multiple products' data, you may encounter various obstacles that can hinder your progress and affect the reliability of your data extraction process. Scaling your scraping solution requires careful consideration of potential challenges and implementing robust strategies to overcome them. Here are a couple of them and how you can address them.
Scaling Amazon Scraping Solution: Proven Techniques to Overcome Challenges
1. Handling different page structures: Amazon's page structure can vary depending on the product, category, or region. Your script might break if it encounters a page with a different structure.
Solution: Implement more robust parsing logic, use more general selectors, or use a more advanced parsing library like lxml or parsel.
2. Rate limiting and IP blocking: Amazon might block your IP or limit the number of requests from your IP if you send too many requests in a short period.
Solution: Implement rate limiting, use a proxy server or a VPN or a rotating proxy solution like Ujeebu.
3. Handling JavaScript-generated content: Some Amazon pages use JavaScript to load content dynamically. BeautifulSoup won't be able to parse this content.
Solution: Use a headless browser like Selenium, Playwright or Puppeteer to render the page and then parse the HTML. Check this tutorial on how to build a simple scraper with Puppeteer. You can also use network captures to optimize your data collection.
4. Dealing with anti-scraping measures: Amazon employs several anti-scraping measures like CAPTCHAs or honeypots to prevent bots from scraping their content.
Solution: Implement rotating proxies, and rotating User Agents, use headers, cookies, and CAPTCHA solvers or use a service that provides these capabilities. Be cautious, as some anti-scraping measures might be illegal to bypass.
5. Compliance with Amazon's terms of service: Make sure your scraping solution complies with Amazon's terms of service and robots.txt file.
Solution: Review Amazon's terms of service and robots.txt file, and ensure your solution doesn't violate any rules or restrictions.
While it's possible to tackle the challenges of Amazon scraping on your own, using a dedicated web scraping service like Ujeebu can save you time and resources. With Ujeebu, you can scale your Amazon scraping project quickly along with compliance, as its cloud-based infrastructure can handle large-scale projects effectively and efficiently.
Ujeebu's simple, easy-to-use API allows you to focus on extracting valuable insights from Amazon data without worrying about the complexities of web scraping. Plus, Ujeebu's rotating proxy system ensures reliability, so you don't have to worry about your requests being blocked. Additionally, Ujeebu offers advanced features like language detection, text analysis, and rule-based data extraction, making it a comprehensive solution for your web scraping needs. By choosing Ujeebu, you'll save time and resources that would be spent on developing and maintaining your web scraping infrastructure, allowing you to focus on what matters most - extracting valuable insights from Amazon data.
Guide to Scrape Amazon Product Data with Ujeebu
Let’s get started:
- Once you sign up, you will get 5000 free credits without sharing credit card details to test the API thoroughly. You will see this dashboard which will give a brief overview of the usage information, API key and balance in your account.
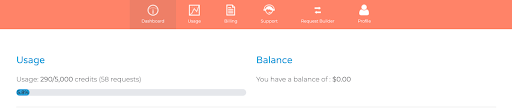
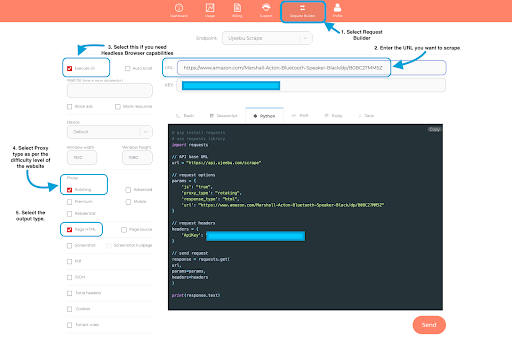
2. The request builder UI feature makes it incredibly easy to use.
a. Select the Request Builder from the top navigation bar,
b. Enter the URL you want to scrape
c. Select `Execute JS` if you need javascript rendering. For scraping Amazon, make sure you select it.
d. Select the proxy type.
e. Select the output type.
f. Click `send` to try the script in the UI.
3. If you want to run this code on your local machine, you can copy the code, paste it into your favourite IDE and run using the `python3 amazonScraper.py` command.
import requests
from bs4 import BeautifulSoup
url = "https://api.ujeebu.com/scrape"
params = {
'js': "true",
'proxy_type': "rotating",
'response_type': "html",
'url': "https://www.amazon.com/Marshall-Acton-Bluetooth-Speaker-Black/dp/B0BC27MM5Z"
}
headers = {
'ApiKey': "<enter-your-api-key>"
}
response = requests.get(url, params=params, headers=headers)
soup = BeautifulSoup(response.text,"html.parser")
title = soup.find('span', {'id':"productTitle"}).getText().strip()
price = soup.find('span', {'class':"aok-offscreen"}).getText().strip().split(" ")[0]
rating = soup.find('i', {'class':"a-icon a-icon-star a-star-4-5 cm-cr-review-stars-spacing-big"}).getText().strip()
description = soup.find('div', {'id':"productDescription"}).getText().strip()
print(f"Title: {title}, Price: {price}, Rating: {rating}, Description: {description}")The code snippet above sets up a request to the Ujeebu API to scrape a specific Amazon product page. The code defines two dictionaries:
1. params: specifies the parameters for the API request, including:
a. js: enables JavaScript rendering on the page.
b. proxy_type: uses a rotating proxy to make the request.
c. response_type: specifies that the response should be in HTML format.
d. url: the URL of the Amazon product page to scrape.
2. headers: specifies the API key to use for authentication.
Running the code above will produce the following output:

An easier approach: using Ujeebu's Extract Rules Parameter
We saw previously how BeautifulSoup can be used in conjunction with Ujeebu's API. While Ujeebu pulls the request HTML, Beautiful Soup extracts the info bits needed.
Alternately, you can use Ujeebu's `Extract rules` and add the rule in this format below :
{
"key_name": {
"selector": "css_selector",
"type": "rule_type" // 'text', 'link', 'image', 'attr', or 'obj'
}
}For example, to extract `productTitle`, the rule would be

If you'd like to extract Product title, price, rating and description all in one go, simply pass this to the rules parameter and it will return the extracted data in JSON format:
{
"title": {
"selector": "span#productTitle",
"type": "text"
},
"price": {
"selector": "span.aok-offscreen",
"type": "text"
},
"rating": {
"selector": "i.a-icon.a-icon-star.a-star-4-5.cm-cr-review-stars-spacing-big",
"type": "text"
},
"description": {
"selector": "div#productDescription",
"type": "text"
}
}The full code is as follows:
# pip install requests
# use requests library
import requests
// API base URL
url = "https://api.ujeebu.com/scrape"
// request options
params = {
'js': "true",
'proxy_type': "rotating",
'response_type': "json",
'url': "https://www.amazon.com/Marshall-Acton-Bluetooth-Speaker-Black/dp/B0BC27MM5Z",
'extract_rules': "{ \"title\": { \"selector\": \"span#productTitle\", \"type\": \"text\" }, \"price\": { \"selector\": \"span.aok-offscreen\", \"type\": \"text\" }, \"rating\": { \"selector\": \"i.a-icon.a-icon-star.a-star-4-5.cm-cr-review-stars-spacing-big\", \"type\": \"text\" }, \"description\": { \"selector\": \"div#productDescription\", \"type\": \"text\" } }"
}
// request headers
headers = {
'ApiKey': "YOUR_API_KEY"
}
// send request
response = requests.get(
url,
params=params,
headers=headers
)
print(response.text)The output will look something like this:
{
"success": true,
"result": {
"title": " Marshall Acton III Bluetooth Home Speaker, Black ",
"price": " $279.99 ",
"rating": null,
"description": null
}
}Conclusion
In this article we provided a step by step guide to scraping data from Amazon product pages. We outlined the different challenges to doing this at a large scale and proposed solutions. We highlighted how scraping APIs like Ujeebu handle these difficulties internally to allow developers to focus on the data extraction aspect of their scrapers. We also showed how Ujeebu also helps with data extraction by providing access to its built-in rule-based parser that only returns the data needed, and in doing so offloading your programs from the parsing process resulting in quicker more nimble scraping scripts/applications.
FAQs
Is scraping Amazon legal?
Scraping publicly available data on the internet, including Amazon, is generally considered legal. This includes extracting information such as product descriptions, details, ratings, prices, and the number of reactions to a particular product. However, caution is necessary when dealing with personal data and copyright-protected content.
For example, scraping product reviews might involve personal data like the reviewer's name and avatar, and the text of the review itself could be subject to copyright protection. Always exercise caution and consider consulting with a lawyer when scraping this type of data.
Does Amazon allow data scraping?
Although scraping publicly available data is legal, Amazon often takes measures to prevent it. These measures include rate-limiting requests, banning IP addresses, and using browser fingerprinting to detect scraping bots. Amazon typically blocks web scraping by responding with a 200 OK success status code that requires passing a CAPTCHA or with an HTTP Error 503 Service Unavailable, sometimes suggesting contact for a paid API.
While there are ways to circumvent these measures, ethical web scraping practices can help avoid triggering them. This includes limiting the frequency of requests, using appropriate user agents, and avoiding excessive scraping that could negatively impact the website's performance.
How can I avoid getting banned while scraping Amazon?
To minimize the risk of getting banned while scraping Amazon, follow these best practices:
Limit Request Rates: Avoid sending too many requests in a short period.
Avoid Peak Hours: Perform scraping during off-peak hours to reduce server load.
Rotate Proxies: Use proxy services to rotate IP addresses and avoid detection.
Use Appropriate User Agents and Headers: Mimic legitimate browser behaviour, and keep your bot’s browser fingerprint similar to a real user.
Extract Only Necessary Data: Focus on the specific data you need to minimize impact.
Take Legal Advice: Ensure you comply with Amazon's terms of service and robots.txt file, and consult with a legal expert to ensure your scraping activities are lawful and respectful of Amazon's intellectual property.
Consider Services like Ujeebu: Utilize services like Ujeebu that provide scalable, reliable, and easy-to-use web scraping solutions, ensuring compliance with Amazon's terms of service and minimizing the risk of getting banned.
By following these guidelines, you can ethically and efficiently extract useful data from Amazon while reducing the risk of getting banned or facing legal consequences.
